重磅!苹果AirPods将推出实时翻译功能,网友:干翻一批AI智能眼镜!

彭博社:苹果AirPods将推出实时翻译功能,网友:这是要干翻一批AI智能眼镜!Oculus联创的AI眼镜公司发布“前段时间火爆全网的语音助手”的基础模型……

苹果将在今年晚些时候为AirPods推出实时翻译功能
苹果正在开发一项功能,让AirPods能够将面对面对话从一种语言翻译成另一种语言,据彭博社报道。该功能将与iOS 19关联,并将在今年晚些时候通过AirPods软件更新推出。

AirPods将能为说不同语言的人提供更简便的翻译过程,不过这一流程将依赖于iPhone上的翻译应用。
如果一位佩戴AirPods的英语使用者正在与说西班牙语的人交谈,iPhone将检测音频,翻译语音,然后将其以英语传回给佩戴AirPods的人。英语使用者随后可以回应,而他们的回应将被翻译成西班牙语并通过iPhone播放出来。苹果的iPhone翻译应用目前已经可以用于这类对话,但将此功能集成到AirPods中将使交流更加流畅。
配合这一新AirPods功能,苹果还计划在iOS 19中改进翻译应用,不过目前尚无具体细节。虽然苹果正在开发计划于2025年推出的新款AirPods Pro 3耳机,但看起来苹果可能也会将iOS 19的翻译功能引入现有机型。
近年来,苹果一直将AirPods更新与iOS更新相结合。例如,在iOS 18中,苹果添加了一系列听力健康功能,可以测试听力问题,并在检测到问题时将AirPods用作助听器。
网友:这个功能将干翻一批主打AI耳机和智能眼镜翻译的产品

Oculus联创的AI眼镜公司发布“前段时间火爆全网的语音助手”的基础模型
AI眼镜公司Sesame发布了为其令人印象深刻的逼真语音助手Maya提供支持的基础模型。
该模型大小为10亿参数,采用Apache 2.0许可证,这意味着它几乎没有限制地可以用于商业用途。根据 Sesame 在AI开发平台Hugging Face上的描述,这个名为CSM-1B的模型可以从文本和音频输入生成”RVQ音频代码”。
RVQ指”残差向量量化”,这是一种将音频编码为称为代码的离散标记的技术。RVQ被用于许多最新的AI音频技术中,包括谷歌的SoundStream和Meta的Encodec。
CSM-1B使用Meta的Llama系列模型作为骨架,并配合音频”解码器”组件。 Sesame 公司表示,CSM的一个微调变体为Maya提供支持。
“这里开源的模型是一个基础生成模型,” Sesame 公司在CSM-1B的Hugging Face和GitHub代码库中写道。”它能够产生各种声音,但尚未针对任何特定声音进行微调[…]由于训练数据中的数据污染,该模型对非英语语言有一定的处理能力,但效果可能不太好。”
Oculus联合创始人杀入AI眼镜赛道,智能语音助手发布,外网惊呼”语音恐怖谷效应没了”

这背后的公司名为Sesame,获得了来自a16z、Spark Capital和Matrix Partners的未披露金额投资——这些都是Oculus VR的重要投资者。公司由Oculus联合创始人兼前CEO Brendan Iribe、Ubiquity6前首席技术官兼联合创始人Ankit Kumar,以及Meta Reality Labs前研究工程总监Ryan Brown领导。
该公司表示,它还在开发配套的AI眼镜,这些眼镜”设计用于全天佩戴,为你提供高质量音频,让你方便地接入可以与你一起观察世界的AI伴侣。”目前,公司只分享了一些看起来像早期原型的小图片。

Sesame在其网站上发布了一份简短的白皮书, 描述了其模型和约一百万小时的”公开可用音频”数据集。公司计划开源其模型,并在”未来几个月内”将支持的语言从英语扩展到20多种。
Brendan Iribe 在2018年离开 Facebook,Iribe 与 Facebook 高管团队在 Oculus (后来的Quest)的未来发展方向上存在“根本性的分歧”,且这种分歧随着时间的推移愈发严重。此外,Iribe 对在性能上进行“逐底竞争”不感兴趣。

为AI眼镜预热!首发的语音助手在X上引起网友一片惊叹~
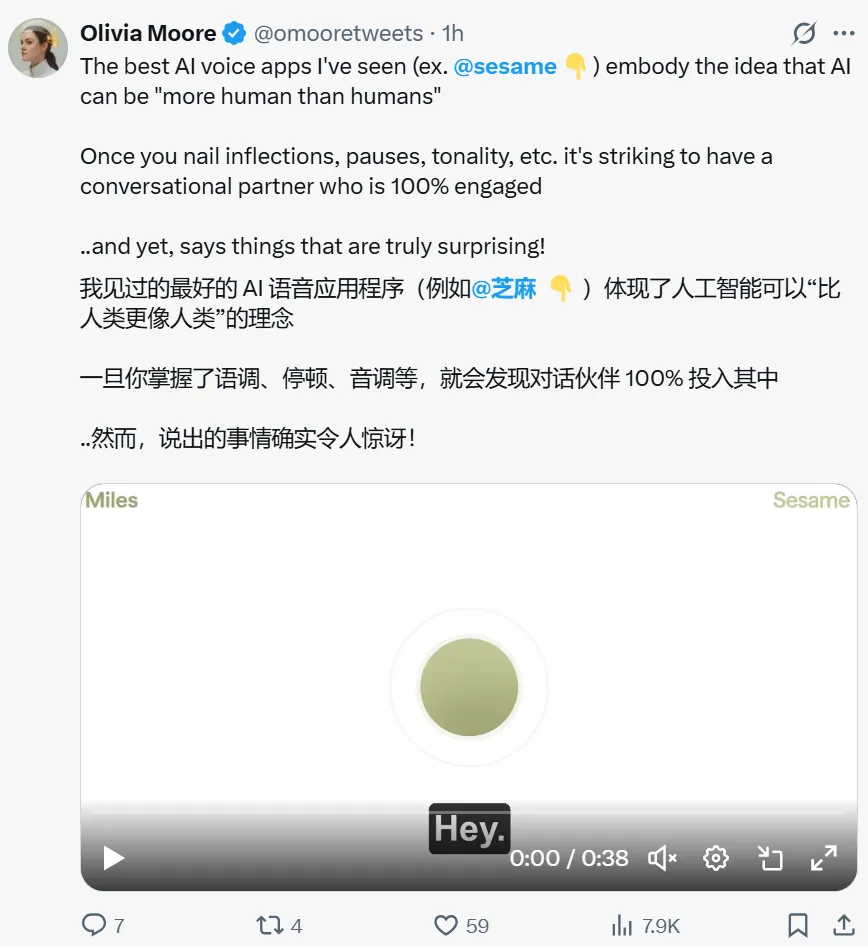
a16z负责人表示是其见过的最好的 AI 语音应用程序,体现了人工智能可以“比人类更像人类”的理念 一旦你掌握了语调、停顿、音调等,就会发现对话伙伴 100% 投入其中
顶尖VC投资人Deedy表示这是语音AI的GPT-3时刻
a16z解释为什么投资这家AI眼镜公司:
智能手机之后,什么将取而代之?是你会真正愿意与之对话的人工智能眼镜。
几十年来,计算机交互界面一直在不断发展,变得更加自然和直观。20世纪80年代,我们使用键盘与终端进行交互。20世纪90年代,我们转而使用鼠标与个人电脑图形用户界面(PC GUIs)进行交互。随后,在2010年代,智能手机引入了触摸屏,用于与移动图形用户界面(mobile GUIs)进行交互。
每一代技术都使人类与机器之间的无缝互动更近一步。但自从iPhone发布以来已经过去了十多年,我们仍然几乎完全依赖屏幕来完成所有操作。那么,接下来会是什么呢?
答案可能在于语音,这是人与人之间互动的自然方式,但在人与计算机的互动中,除了像“Alexa,关灯”这样的基本体验外,语音一直显得过于原始。
然而,人工智能在过去几年里取得了巨大进步。结合合适的硬件,语音和语言(包括理解和生成)方面的进步可能会解锁一种真正自然的计算机交互界面。这就是芝麻人工智能登场的地方。
Sesame 人工智能基于一个简单但并不显而易见的理念,即答案不在于增强现实(AR)眼镜的屏幕中,而在于音频。到目前为止,人工智能音频的情感平淡让人感到疲惫且不自然。但如果你从AR眼镜中去掉视觉显示,转而专注于一个以音频为主的出色人工智能系统,你就能创造出一种无缝且直观的计算体验。
作为一个起点,该团队已经训练了一个会话语音模型(Conversational Speech Model,CSM),它采用了一种新颖的语音建模方法,你可以在这里了解更多相关内容。它尚未完全跨越“恐怖谷”(uncanny valley,指人类对机器人或虚拟人物的仿真度越高,越容易产生厌恶感的现象),但已经接近了。你还可以尝试这个研究预览版,并在这里与它的首批人工智能伙伴Maya或Miles进行对话。
参考:
https://techcrunch.com/2025/03/13/sesame-the-startup-behind-the-viral-virtual-assistant-maya-releases-its-base-ai-model/
—— End ——








